Data Warehouse vs. Data Lake: How to Decide What Your Business Needs
Data UniversityThe choice between a data warehouse and a data lake represents one of the most fundamental architectural decisions organisations face when building their data infrastructure. While both serve as centralised repositories for storing organisational data, they differ significantly in their approach, purpose, and capabilities.
In this article, we'll dive into specifications of both approaches as they both have benefits and cons for your infrastructure and answer the ultimate question: What are the key differences between a data lake and a data warehouse?
Understanding Structured and Unstructured Data
Before going any further, let's explain the difference between unstructured data and structured data and why they matter in picking the right approach for your organisation?
Structured data are, naturally, data that are structured. They use a standardised format and schema to provide information. Generally, they are organised into tables that ensure a consistent analysis. For example, a completed database containing customer IDs, names and transaction amounts can be queried and analysed without changing the structure.
There are three types of structured data: relational data, which is stored into tables with rows and columns, as mentioned above. Hierarchical data follows a hierarchical structure, where each data element has a parent and possibly multiple children. Lastly, tabular data are organised into tables, with rows representing records and columns representing attributes.
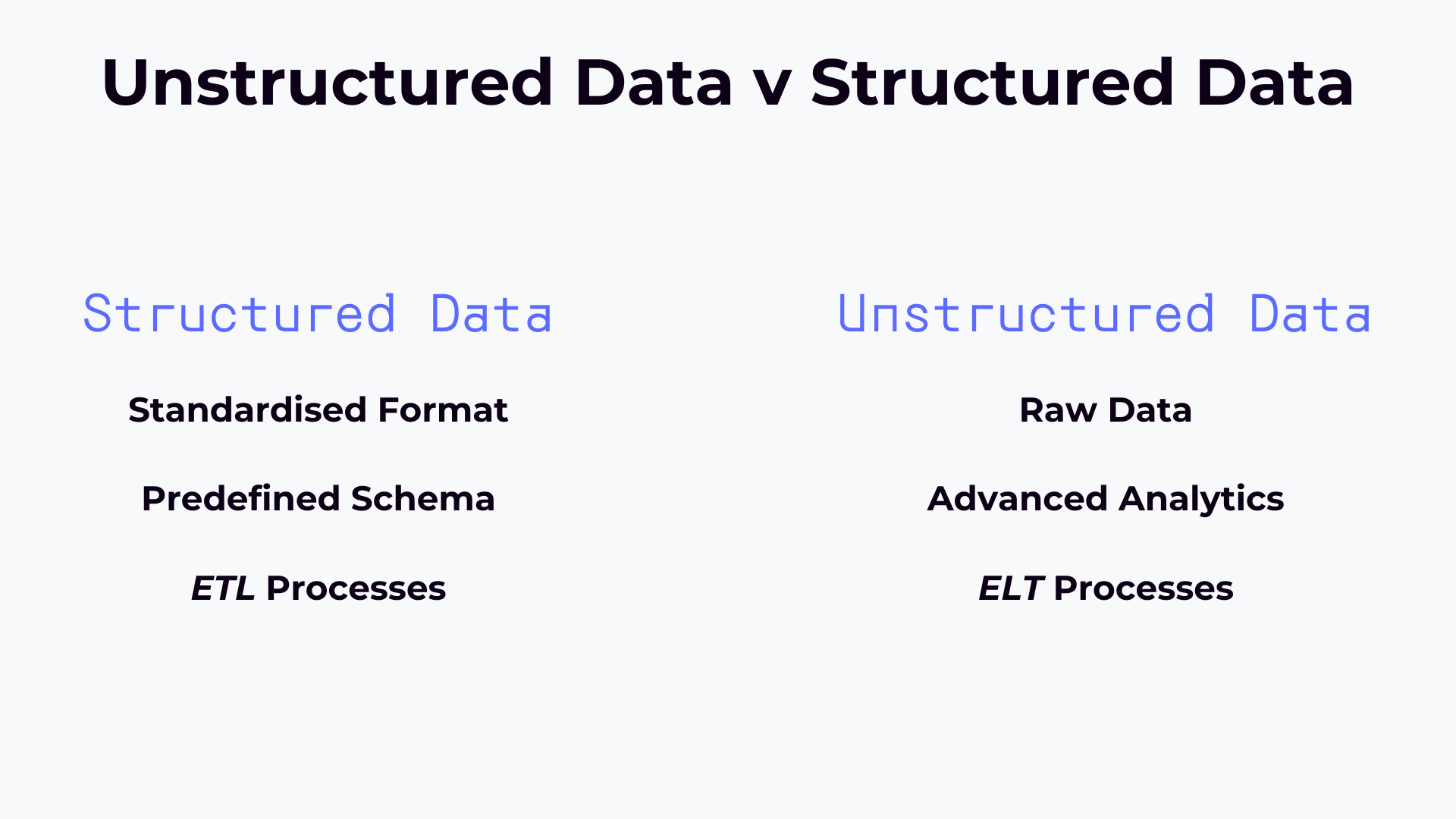
In contrast, unstructured data lacks a consistent schema. This type of data is not readable at first and mostly includes audio or video files or documents. To extract meaningful insights, advanced techniques from machine learning for example are required.
But why use unstructured data? The answer is simple: ingesting unstructured data enables organisations to collect a wider variety of information from a range of diverse sources.
Now that we have seen the differences between unstructured data v structured data let's focus back on the main topic!
The Purpose and Role of a Data Warehouse
The purpose of a data warehouse is to facilitate the analysis and reporting of data. To this end, it stores processed and cleaned data that has been transformed into a consistent format using structured data and a predefined schema. Think of it as a highly organised library where every book has been carefully cataloged and placed in its proper location.
The data ingested into the infrastructure undergoes an ETL (Extract, Transform, Load) process. This ensures the quality of the raw data before it enters the warehouse. This preprocessing makes queries fast and reliable, which is why data warehouses remain the backbone of business intelligence operations.
The Data Warehouse's design makes it particularly effective for generating regular reports, dashboards, and answering predefined business questions with speed and accuracy.

An Overview of the Data Lake Concept
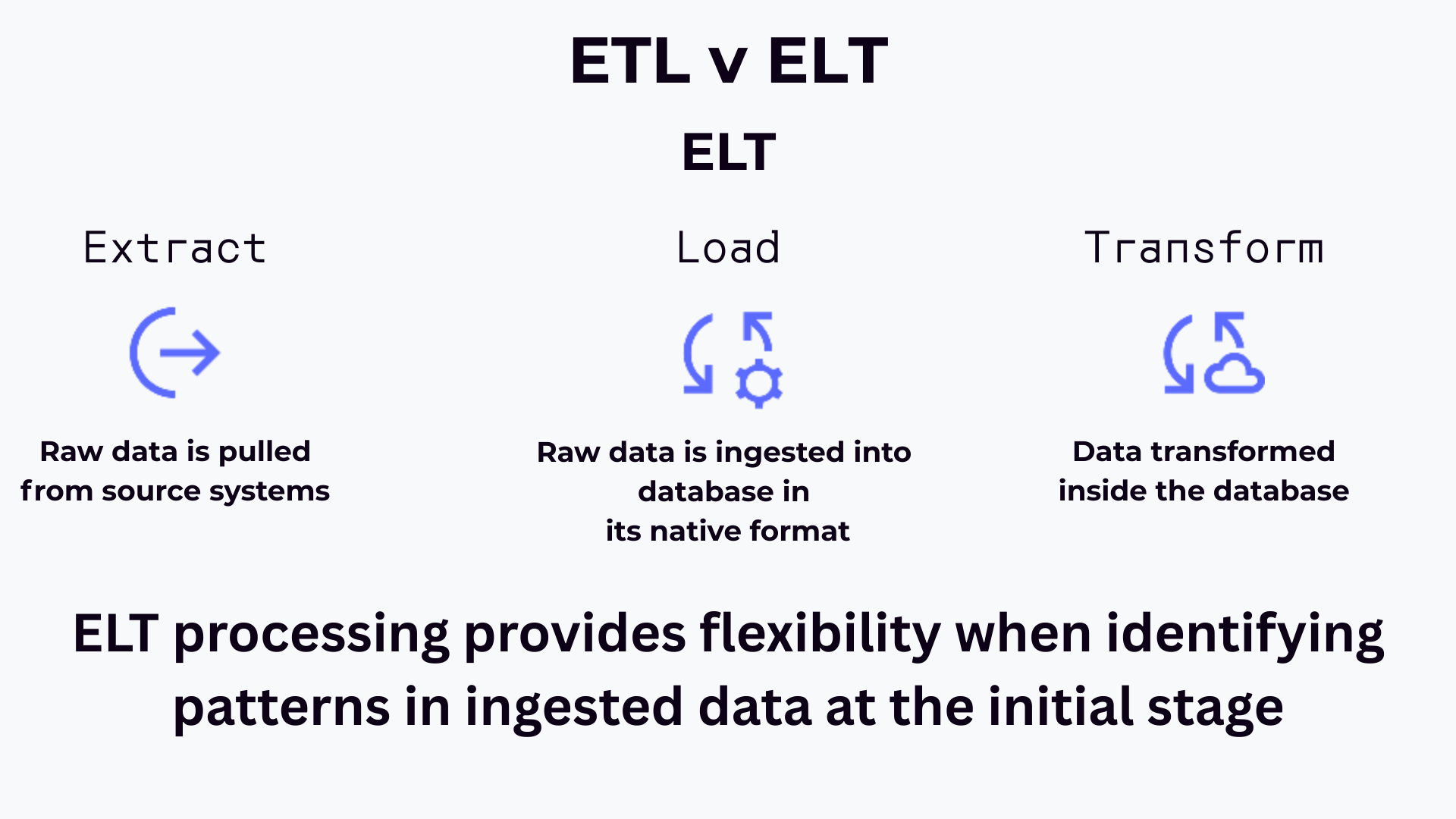
A data lake takes a fundamentally different approach by storing raw, unprocessed data in its native format. It's more like a reservoir that accepts any type of data. It does not require upfront organisation or transformation.
This flexibility makes data lakes ideal for organisations dealing with diverse data sources, and those pursuing advanced analytics like machine learning, where having access to raw data can reveal patterns that might be lost in preprocessing. Data lakes typically use object storage on cloud platforms, making them cost-effective for storing massive volumes of information.
The architecture follows an ELT (Extract, Load, Transform) approach, where data is stored first and transformed only when needed for specific use cases. This enables greater agility, but requires more sophisticated tools and expertise to extract value from the data.
Structural, Performance, and Cost Differences in Data Storage Systems
The structural difference is perhaps most evident: data warehouses require schema-on-write, meaning you must define the data structure before loading it, while data lakes use native raw data, allowing you to determine how to interpret the data when you need it.
Performance characteristics also diverge significantly. Data warehouses deliver faster query performance for structured, analytical queries because the data has been optimised for such operations. Data lakes may require more processing time, but offer flexibility for exploratory analysis and handling diverse query types.
There are also differences relating to costs: building a data warehouse infrastructure often requires higher storage costs, due to their optimised infrastructure. However, the cost for processing queries is lower in contrast to data lake's processing due to more complex queries.
The target user differs, as well. Data Warehouses primarily serve business analysis, where they need consistent data for reliable answers to queries. Data lakes attract data scientists, machine learning engineers, and researchers, who need flexibility to experiment with diverse data types and analytical approaches.
Use Cases and Strategic Considerations for Data Warehouses and Data Lakes
Organisations with well-defined reporting needs, structured data sources, and regulatory compliance requirements often find data warehouses more suitable. Industries like finance, retail, and healthcare have traditionally relied on data warehouses for their critical reporting and analytics.
Data lakes make more sense when dealing with high volumes of diverse data, pursuing advanced analytics like predictive modelling, or when future use cases remain undefined. Technology companies, research institutions, and organisations investing heavily in artificial intelligence often favour data lakes.
Many modern organisations are moving toward a hybrid approach, sometimes called a data lakehouse, which attempts to combine the structured reliability of warehouses with the flexibility of lakes. Most enterprises choose to embrace this path with both capabilities to fully leverage their data assets.
The decision ultimately depends on your specific needs around data types, analytical requirements, existing infrastructure, team capabilities, and budget constraints. Rather than viewing this as an either-or choice, consider how each technology might serve different aspects of your data strategy.
However, implementing either solution—or transitioning between them—presents significant change management challenges. Organisations often struggle with migrating legacy systems, retraining teams on new tools and methodologies, establishing new data governance frameworks, and managing the cultural shift from traditional reporting to more exploratory analytics.
To be successful, it is not enough to implement the technology; you also need to secure stakeholder buy-in, develop new skill sets across teams and create clear policies around data access and quality. As these organisational challenges are often more difficult than the technical ones, a phased approach with strong executive sponsorship is essential for sustainable adoption.